Collector
This configuration tab contains the classification engine settings. Each configuration option has an associated “i” which describes the nature of the setting.
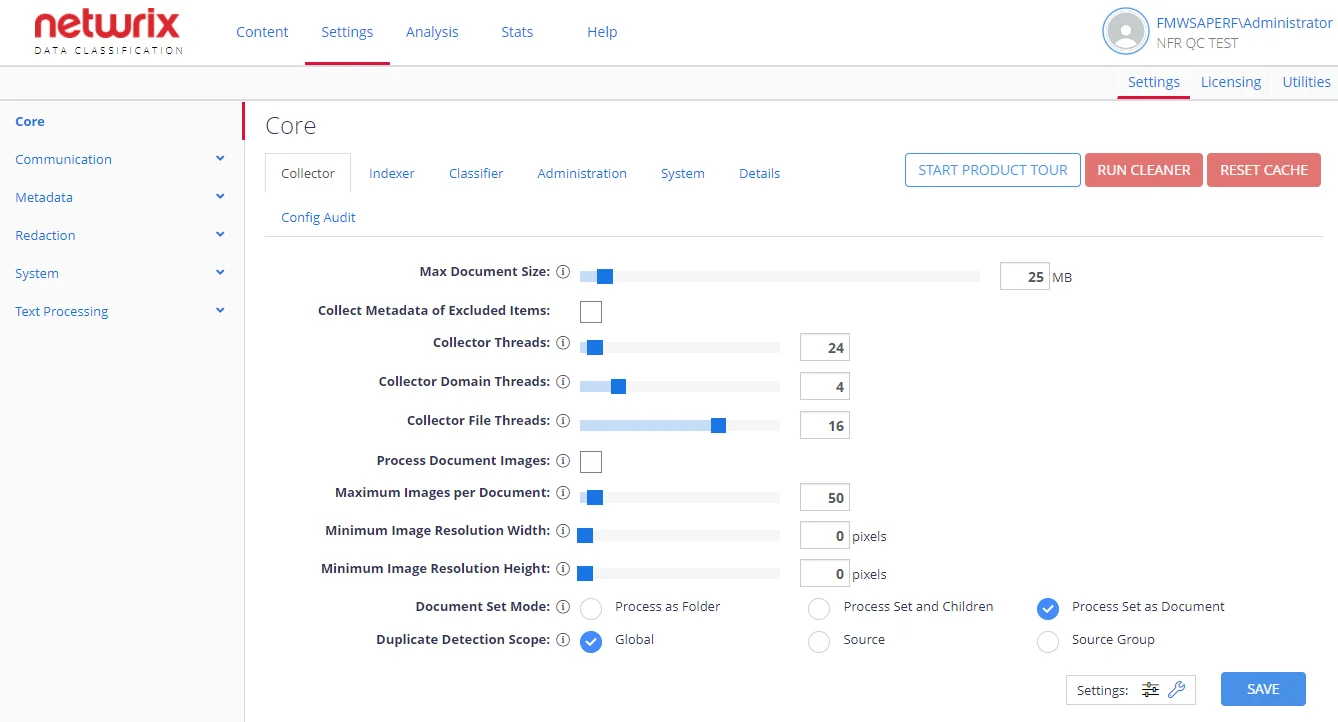
| Option | Description | Comment |
|---|---|---|
| General settings | ||
| Max Document Size | Sets the maximum size of the document to be processed. | Documents exceeding this size will typically be excluded from processing. |
| Collect Metadata of Excluded Items | When enabled, the Netwrix Data Classification services will include the document, but from a metadata standpoint only (no text will be extracted from the file). | Used in combination with the "Max Document Size" value. Inactive by default. |
| Collector Threads | The number of overall background threads to be utilized by the Collector to access content from the source system. | Each thread can be considered a "user" when considering load on the source system. For more information, see this Knowledge Base article. |
| Collector Domain Threads | The number of threads to be utilized by the Collector to access content from the each HTTP domain. (Examples: netwrix.com, google.com, microsoft.com, etc.) The number will be automatically capped by the "Collector Threads" value. | Applies to HTTP source types only. Each thread can be considered a "user" when considering load on the source system. For more information, see this Knowledge Base article. |
| Collector File Threads | The number of threads used to crawl file system content. | For more information, see this Knowledge Base article. |
| Process Document Images | If enabled, images will be extracted from supported documents ( (Office XML files and PDFs). These images will be then collected, and any text found will be included (with the document text) for classification. | For this setting to be applied, OCR must also be enabled at a content type level — to ensure that the extracted images are run through the OCR engine. This setting is inactive by default. |
| Maximum Images per Document | Maximum amount of images to process through OCR on a per document basis. | |
| Minimum Image Resolution Width | Minimum resolution (in pixels) of images to process through OCR. | |
| Minimum Image Resolution Height | Minimum resolution (in pixels) of images to process through OCR. | |
| Document Set Mode | Specifies how SharePoint document sets will be treated. Possible options: - Process as Folder — Classifications will only be written to the child items. - Process Set and Children— Classifications will be written to both the root item and individual children. - Process Set as Document (default) — Classifications will only be written to the root item. | Applies to SharePoint documents. |
| Duplicate Detection Scope | Instructs to exclude detected duplicates from processing within the specified scope: Global, Source, Source Group | Applies to File and web sources. |
| Advanced settings | ||
| Collector User Agent | Is used by Collector service as part of each web request made when crawling HTTP sources — to identify itself to the crawled systems. | |
| Encrypt Text (text.cse) | Encrypts all data stored in text.cse (raw document extracts). | Inactive by default. If data already exists in the index, then to enable encryption on that existing data, you should perform re-collection. For that, click Run Cleaner button on the right. |
| Optimise Text Storage | Reduces storage requirements for stored text. | Enabled by default. At each re-crawl or re-index the programs tries to detect whether the document text has changed. |
| Re-use Text Offsets | Reduces storage requirements for stored text by sharing and reusing the stored text. | May slightly increase the SQL demands —in order to process each de-duplication command. |
| Collector Delay | The sleep time (in milliseconds) between intensive operations, such as storing crawled text. Default is 1 ms. | |
| Collector Polling | The sleep time (in seconds) between Collector batches. | Only utilized when the Collector queue is empty. |
| iFilter Processing Mode | Specify where the iFilter processing will run. Possible options: Process as Sub Process— run in a separate process Process Internally — run within Collector process | |
| Collector Reader Process Pool Size | The number of external processes that will be utilized for iFilter conversion. | Each additional process adds additional load on the Netwrix Data Classification server. We recommend leaving this setting on its default value. For more information, see this Knowledge Base article. |