Suggestions
Clues can be used to statistically produce a list of suggested clues that can be assigned to the term.
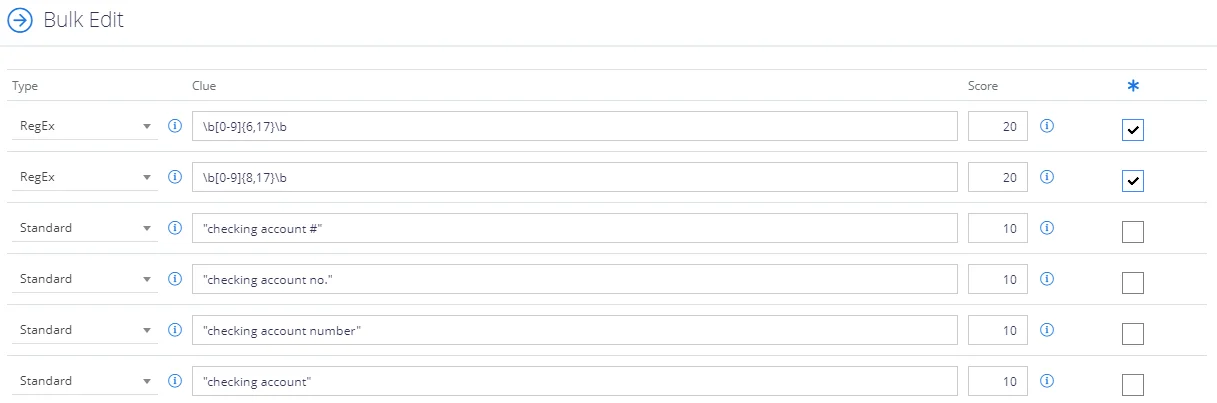
Clues can be suggested for a term via the following methods:
- Suggest Clues for whole term: Click on the Suggest Clues for class link under the class heading to produce a list of suggestions, based on all existing clues in the class.
- Single Clue: Click on the Suggest link against each clue to produce a list of suggestions, based on only this clue.
- Class Document: Click on the Suggest link against each class document to produce a list of suggestions, based on the document.
Once the list of suggested clues has been generated they can be selected and added to the term clues:
NOTE: Changes made to a class will have no effect unless documents are re-classified.
The clue type can be set to one of the following:
- Standard
- Case-Sensitive
- Phonetic
- Create Tree Node
NOTE: If Create Tree Node is selected then these topics shall be added as children of the currently selected node in the taxonomy structure.
Adding a Clue
To add a new clue, go to the topmost row in the list and specify clue properties, as explained below:
- Type
- Clue (rule body)
- Score
- Is Mandatory
When ready, click Insert on the right.
Clue Body
When specifying the clue body, consider exact matching and stemming explained below.
Exact Matching
There may be any number of words up to a maximum of 200 characters per clue. However, most clues will consist of one, two or three words.
Use double quotes around phrases to invoke exact phrase matching.
Stemming
Word stemming simplifies classification rules by automatically matching inflected word forms using a single keyword clue. This can be useful to identify how a clue will be implemented by the classification engine. Stemming is supported for the following languages:
- Dutch
- English
- French
- German
- Hungarian
- Spanish
- Portuguese
Hovering over a standard clue will show the stemmed version of the word / compound term.
Example: A class called Global Warming may have the following clues:
- Global Warming
- Greenhouse Gases
- CO2 Emissions
- Pollution

To disable stemming, use double quotes around single words.
Score
Scores are expressed as percentages of the threshold. For example, if the threshold is 50 then:
- 50 = guarantees that this term alone will be sufficient to classify the document
- 25 = this term will get half way to the target
- 10 = this term is of low importance but its presence should boost a document score
- 0 = zero weight – use to disable a clue
- -10 = this term is a small negative indicator
- -50 = this term is a strong negative indicator
- -1000 = the presence of this term should force the document to not be classified
Higher scores indicate a stronger association with the topic.
- Example 1: Global Warming with a score of 50 will cause a document with this concept to be matched.
- Example 2: Pollution with a score of 20 (on its own) will not be sufficient to cause the document as being about global warming.
Consider that clues can also be assigned a negative value, which will prevent incorrect associations.
- Example 3: Noise pollution should not be associated with Global Warming. So Noise pollution would be added with a negative value.
Mandatory Clues
You can use the Mandatory checkbox to indicate that a clue is required, i.e. a document cannot be classified against a category unless it matches all of the mandatory clues.
The mandatory clue selector is denoted by the * icon:
![]()
Using the Local Option
In some cases, a further option will be available per clue: “Is Local?”. This option allows the user to restrict a clue purely to the current Term Set.
NOTE: This option is only available for reused terms (SharePoint Term Sets).

- Once this option is selected, it will not be possible to amend the clue from any other Term Set that contains the re-used Term.
- If you want to share the Term across all Term Sets again, clear the option from the Term Set in which it was originally enabled.
Using Synonyms (SQL taxonomies only)
NOTE: The Synonyms link is only available for the clues in SQL taxonomies.
The Synonyms link can be used to enter synonym definitions.
In general, the use of this facility is not recommended. The preferred approach is to enter each synonym as separate clues. Entering each synonym as separate clues will generally result in more accurate scoring and therefore to better classification results.
Classification Rules (Clues)
Each taxonomy contains a set of terms. Terms are defined by set of configuration rules (also called clues). Clues are used to describe the language found in documents, making these documents belong to a particular topic.
Predefined Classification Rules
The standard taxonomies provided with Netwrix Data Classification include predefined classification rules for personally identifiable information (full name, home address, etc.). They are available in the following languages:
-
English
-
French
-
German
-
Spanish
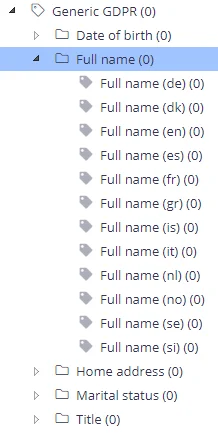
Users can easily extend the out-of-the-box classification rules by adding relevant keywords and terms in other languages.
In addition, there are predefined classification rules for various national identification and registration numbers. These rules typically look for ID patterns supplemented by related keywords for better classification precision.
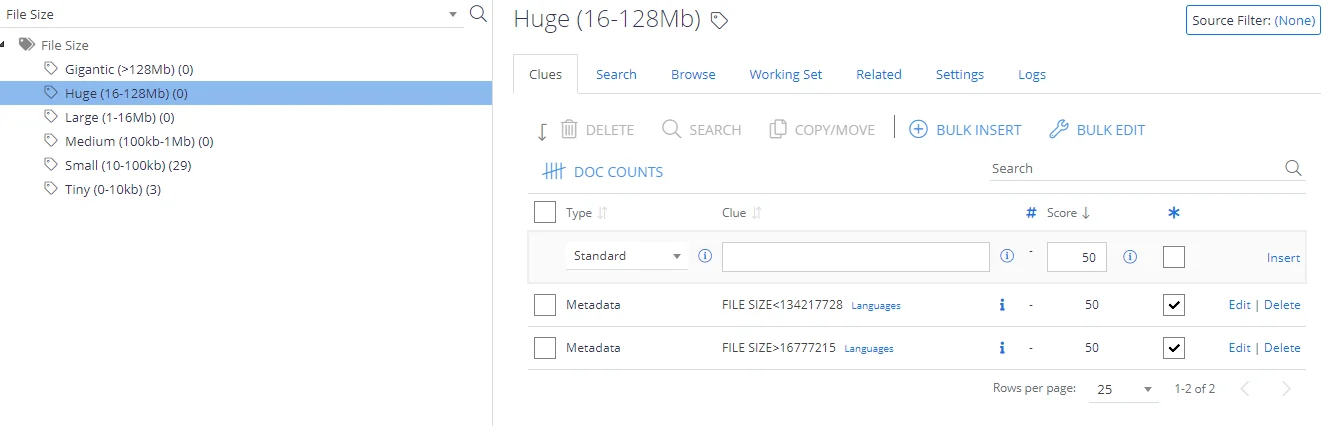
These rules are provided for the following countries (coverage varies):
- Australia
- Brazil
- Bulgaria
- Canada
- Denmark
- France
- Germany
- Hong Kong
- India
- Italy
- Netherlands
- Singapore
- South Africa
- Spain
- Sweden
- United Kingdom
- USA
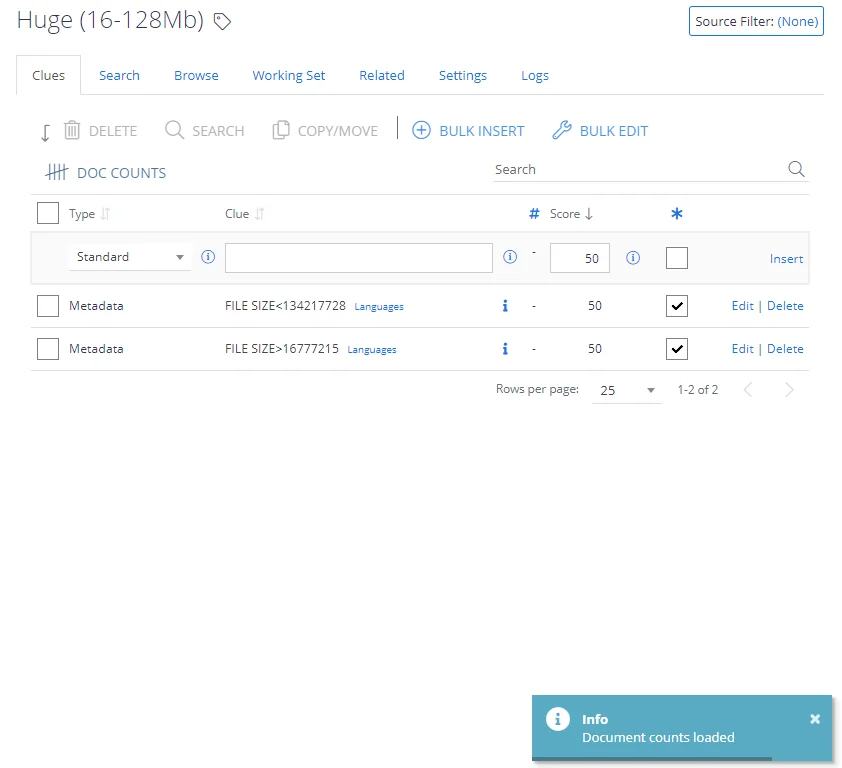
Working with Clues
To work with the clues, select the required subnode (terms set) under the taxonomy tree on the left and then select Clues on the right:
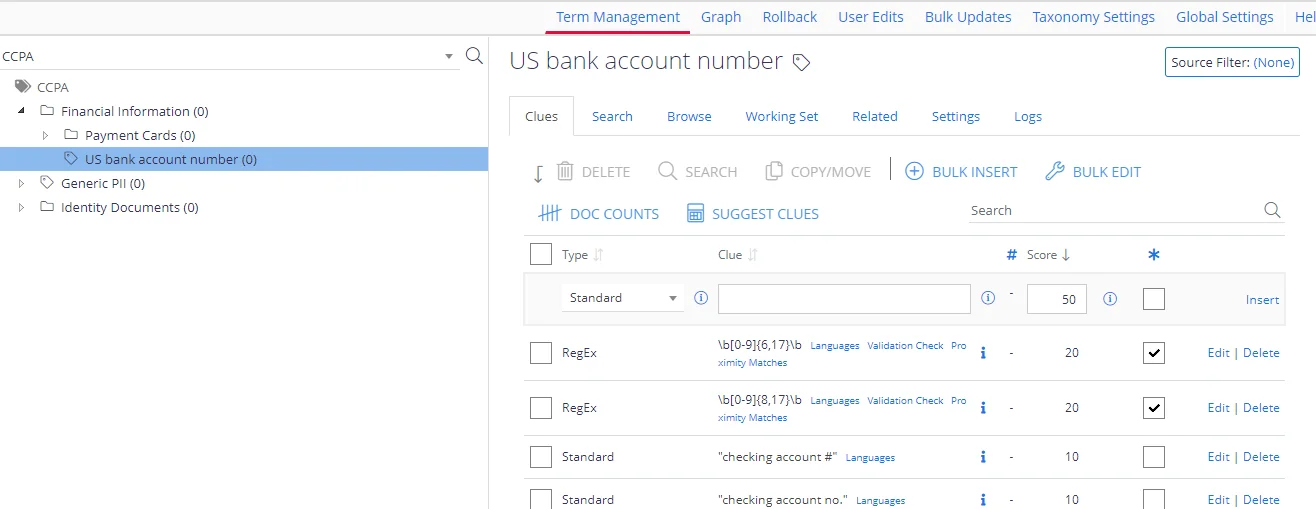
- For each clue in the list, you can view and manage its type, score, and other properties.
- To add a new clue, go to the topmost row in the list and specify its properties.
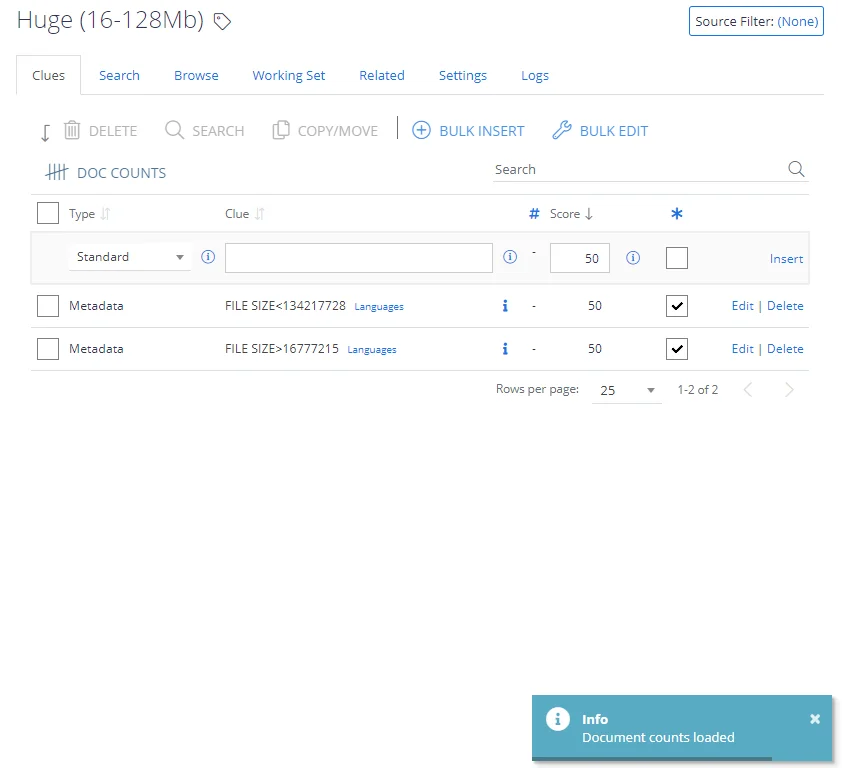
Documents count
Click the Doc Counts link in the top right corner to get the number of documents that match the word / phrase used within the clue:
Suggested Clues
The suggested clues feature facilitates the process of tailoring classification rules in context by offering relevant terms and keywords based on previously indexed file content. This feature is available for all Latin script based languages with increased support for the languages that have support for stemming and/or stop-word analysis:
- Afrikaans
- Danish
- Dutch
- English
- Finnish
- French
- German
- Hungarian
- Italian
- Norwegian
- Spanish
- Portuguese
- Romanian
- Swedish
- Welsh
See also: