How It Works
Netwrix Data Classification identifies and classifies sensitive and business-critical content across your organization. This way it mitigates the risk of data breaches. The program also meets compliance requirements with less effort and expense.
You can view the app architecture and components in the figure below.
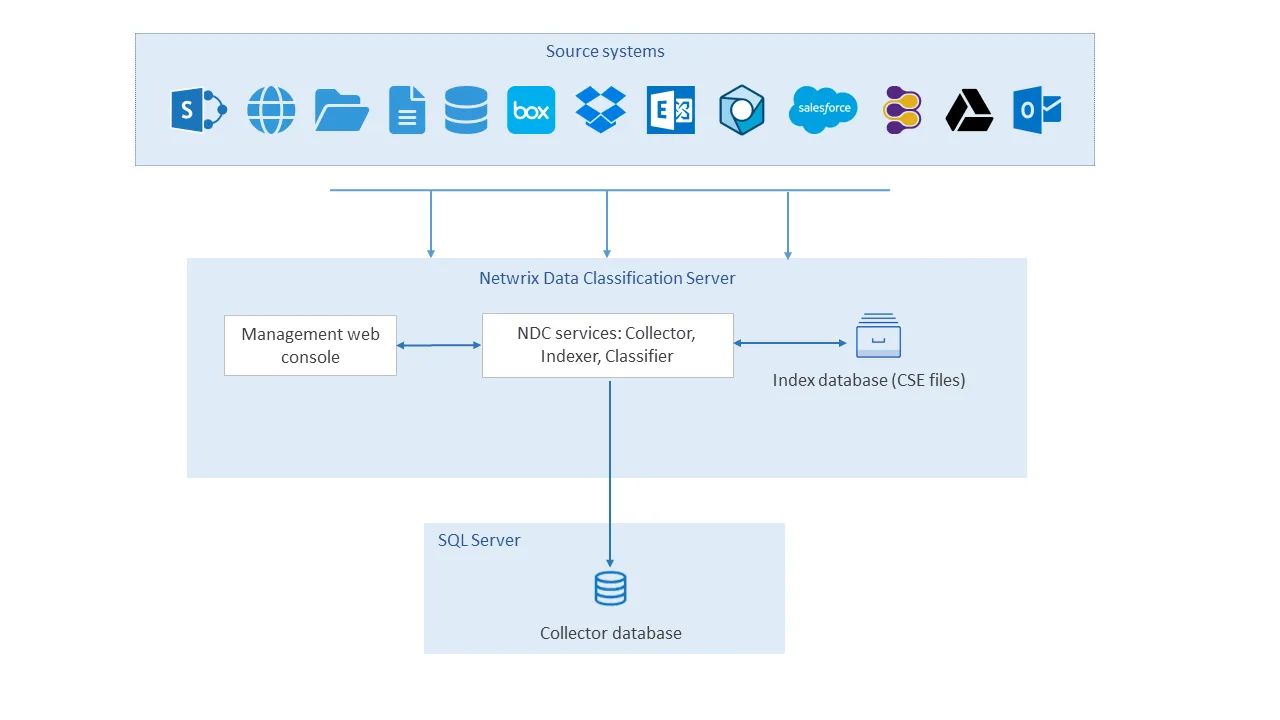
-
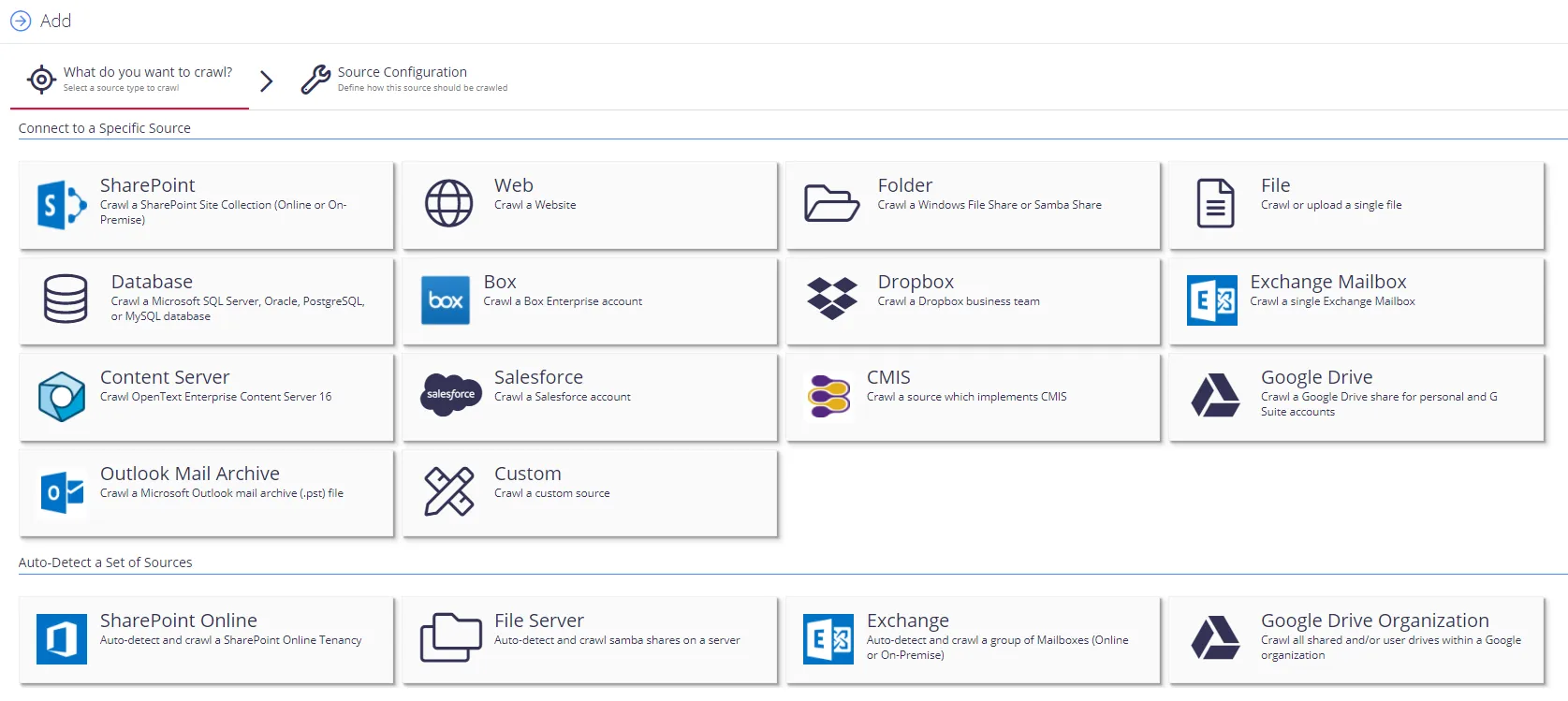
The user adds data sources using the NDC Management web console (Netwrix Data Classification program).
-
The configured data sources are saved in the NDC SQL database (SQL Server Collector Database).
-
The NDC Collector service crawls data files in each data source, converts documents into plain text and populates file metadata in the NDC SQL database.
-
The NDC Indexer service builds and maintains a full-text search index (NDC Index) based on the content and metadata of the collected files.
-
The NDC Classifier service performs data classification by matching collected files against installed taxonomies (e.g., Netwrix compliance taxonomies).
-
If Data Tagging is enabled, the assigned classification labels are written to the custom metadata columns for supported document types.
-
If Remediation Workflows are enabled, the configured workflows are run on documents that meet the workflow conditions.
QueryServer
All interaction between the application and Netwrix Data Classification is via the QueryServer and consists of high-level XML transactions over a Web Services interface.
The primary purpose of the QueryServer is to satisfy retrieval requests from the proprietary probabilistic index (aka NDC Index Database). However, the QueryServer also handles all indexing requests and stores these in the SQL Database for processing by the conceptCollector and Indexer.
NDC Collector
The NDC Collector is responsible for importing new documents into the system.
In addition to collecting documents the NDC Collector also performs the following:
- conversion of documents to text format
- automatic language detection
The NDC Collector manages the queue of documents to be indexed, and outputs its results, via the SQL database.
The NDC Collector is implemented as a Microsoft Windows Service.
Indexer
The Indexer takes each new document collected by the conceptCollector and inserts the appropriate information in the NDC Index Database.
This activity can proceed concurrently with retrieval activity. However, heavy-duty indexing activity can significantly impair retrieval performance and so, if on-going indexing is very significant, then the conceptIndexer should either be run during quiet periods (perhaps overnight) or alternatively new information should be constructed off-line with a batch process updating the live index periodically.
If the Indexer is to update the live index as a background task then it is vital that this process runs on the same server where the NDC Index Database is located.
The Indexer is implemented as a Microsoft Windows Service.
NOTE: For file system and SharePoint/OneDrive sources, event handlers/file watchers dynamically schedule documents for crawling when they are created/modified. You only need to set up reindexing for those sources to catch documents that the event handlers miss.
NOTE: For File Share scans, the source watchers will queue up new and updated documents for crawling automatically. This function even operates when a source is paused. If you want to stop adding any content from specific file shares, add the path for those files shares to the Source Watcher Exclusions.
NDC SQL Database
The NDC SQL Database is used to manage the queue of documents being indexed. It may also be used by the application to store any application-specific information independently from Netwrix Data Classification.
The QueryServer will also retrieve selected information for the current hitlist from the SQL Database such as: the document title, body text, etc. However, this information is always requested using a primary key and so is very efficient. The hitlist itself is always constructed and ranked using information contained in the proprietary conceptDatabase.
The current release of Netwrix Data Classification supports SQL Server 2008 R2 or later.
NDC Index Database
The NDC Index Database contains the probabilistic index to all documents in the system. All files use the extension “.cse” but will use the extension “.tmp” when merging changes into the index.
The NDC Index Database files should normally be located on the same server as the Netwrix Data Classification server due to the fact that the query and indexing processes can be disk intensive. Note that “text.cse” is not supplied since it will be created automatically when the first documents are collected.
Classifier
Classifier can be used to classify documents post index time. When this option is being used then an application can map documents to any external classification system such as a corporate taxonomy or user profiles.
Classification can be used as a method browsing the document collection or to filter ad hoc queries.
The Classifier is implemented as a Microsoft Windows Service.