Processing Settings
On the Processing Settings step, select options for data processing and classification.
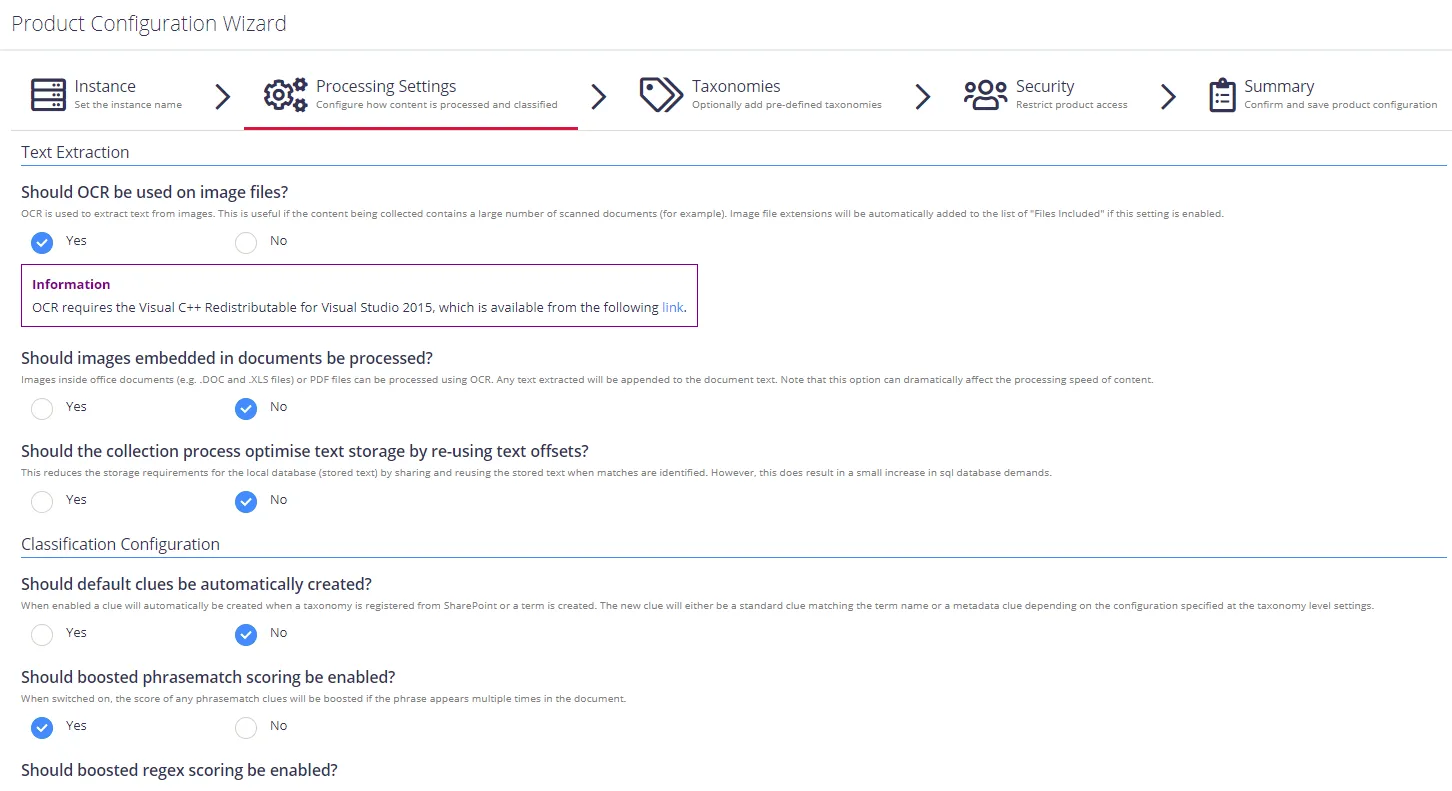
Review the following for additional information:
| Option | Description |
|---|---|
| Text Extraction | |
| Should OCR be used on image files? | Optical Characters Recognition is a technology used to extract text from images. Enable OCR if the content being collected contains a large number of scanned documents (for example). Performing OCR on documents can significantly reduce indexing performance. IMPORTANT! OCR requires the Visual C++ Redistributable for Visual Studio 2015. Visit Microsoft website for downloading. |
| Should images embedded in documents be processed? | Enable this option to recognize documents with integrated images. |
| Should the collection process optimise text storage by re-using text offsets? | Enable this option to use text offsets. |
| Classification Configuration | |
| Should default clues be automatically created? | Enable if you want a clue to be created automatically when a registering taxonomy from SharePoint or term creation. The created clue is standard and matches the term name or a metadata clue depending on the configuration specified at the taxonomy level settings. See Classification Rules (Clues) for more information. |
| Should boosted phrasematch scoring be enabled? | Enable to boost the score of any phrasematch clues if the phrase appears multiple times in the document. |
| Should boosted regex scoring be enabled? | Enable to boost the score of any regex clues if the regular expression appears multiple times in the document. |
| How should regular expressions be processed? | Enables and disables case sensitivity when processing regular expressions. |
| Store trimmed classifications to improve reclassification performance? | Enable to store trimmed classifications to SQL database (trimmed due to the maximum number of classifications being hit for a document). This improves classification performance, however, this may lead to additional data in the SQL database. |
Proceed with adding taxonomies.