Language Support
In general, Netwrix Data Classification is capable of indexing and classifying information in any language through native Unicode support. However, the support level for some advanced product capabilities and out-of-the-box classification rules varies for different languages.
Indexing and Classification
Documents in any language can be indexed and classified thanks to Unicode support and statistical content analysis techniques. This includes Chinese, Greek, Japanese, Russian and other non-Latin based languages.
Languages for Clue
Each clue can be restricted to documents written in a subset of the available languages. This is useful if a word in one language also appears in another language but has a different meaning.
In this case you can click the Languages link beside each clue and select any subset of the available languages:

Language Support
This section explains various aspects of multi-language support in administrative web console. In general, the application is capable of indexing and classifying information in any language through native Unicode support. However, the support level for some advanced product capabilities and out-of-the-box classification rules varies for different languages.
Each clue can be restricted to documents written in a subset of the available languages. This is useful is a word in one language also appears in another language but has a different meaning. In this case you can click the Languages link beside each clue and select any subset of the available languages:
Indexing and Classification
Documents in any language can be indexed and classified thanks to Unicode support and statistical content analysis techniques. This includes Chinese, Greek, Japanese, Russian and other non-Latin based languages.
Stemming
Word stemming simplifies classification rules by automatically matching inflected word forms using a single keyword clue. Stemming is supported for the following languages:
- Dutch
- English
- French
- German
- Hungarian
- Spanish
- Portuguese
Suggested Clues
The suggested clues feature facilitates the process of tailoring classification rules in context by offering relevant terms and keywords based on previously indexed file content. This feature is available for all Latin script based languages with increased support for the languages that have support for stemming and/or stop-word analysis:
- Afrikaans
- Danish
- Dutch
- English
- Finnish
- French
- German
- Hungarian
- Italian
- Norwegian
- Spanish
- Portuguese
- Romanian
- Swedish
- Welsh
Predefined Classification Rules
The standard taxonomies provided with Netwrix Data Classification include predefined classification rules for personally identifiable information (full name, home address, etc.) in the following languages:
-
English
-
French
-
German
-
Spanish
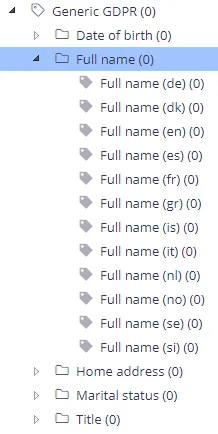
Users can easily extend the out-of-the-box classification rules by adding relevant keywords and terms in other languages.
In addition, there are predefined classification rules for various national identification and registration numbers. These rules typically look for ID patterns supplemented by related keywords for better classification precision.
The rules are provided for the following countries (coverage varies):
- Australia
- Brazil
- Bulgaria
- Canada
- Denmark
- France
- Germany
- Hong Kong
- India
- Italy
- Netherlands
- Singapore
- South Africa
- Spain
- Sweden
- United Kingdom
- USA